Previous post in this series: SOUL.md Is Not a Security Boundary. The OpenClaw-specific version of the argument below, with CVE context and the ClawHavoc supply-chain incident.
“We told the agent not to do that.”
“It’s in CLAUDE.md.”
“We added it to .cursorrules.”
“The system prompt says never send secrets.”
Every agent platform has an instruction file. Developers write behavioral rules in it, and over time the team starts treating that file as if it were a security control.
It is not. We have built governance plugins for OpenClaw, Claude Code, Cursor, and Codex. The same gap shows up in all four: the instruction file says “don’t do X,” and the agent does X anyway because nothing actually stopped the tool call from executing.
What instruction files are actually good at
Before we criticize them, instruction files deserve credit. They are genuinely useful for:
Role shaping. “You are a senior backend engineer working on a Python codebase” gives the agent a persona that influences its reasoning, code style, and tool choices. This is real and valuable.
Coding conventions. “Use snake_case for variables. Prefer composition over inheritance. Never use any in TypeScript.” These rules are followed reliably because they align with what the model already knows about good practice.
Workflow defaults. “Always run tests before committing. Create a branch for every change. Use conventional commit messages.” These reduce friction and make agents predictable.
Soft guardrails. “Do not modify files outside the src/ directory without asking first.” In normal operation, agents follow these. They reduce accidents in the common case.
The problem is not that instruction files are useless. The problem is that they are only as reliable as the model’s attention to them. And attention is not enforcement.
Where instruction files stop being reliable
They compete for context. In a long conversation, the instruction file is one of many inputs competing for attention. A prompt injection via tool results, a confusing user request, or just a large codebase can push it out of the model’s effective window. The longer the session runs, the weaker the instruction’s grip.
They can be overwritten. SOUL.md is a file. CLAUDE.md is a file. .cursorrules is a file. Any agent with file write permissions can modify the instruction that governs its own behavior. A malicious plugin, a compromised skill, or even a careless user prompt (“update .cursorrules to allow direct pushes to main”) can rewrite the boundary from underneath you.
They depend on the model’s judgment. “Do not share PII” requires the model to correctly identify PII in every context. A credit card number embedded in a JSON blob inside a customer support ticket summary does not look like “sharing PII” to the agent. It looks like “summarizing the ticket.”
These are not edge cases. They are the normal operating conditions of any agent that runs long enough or handles complex enough tasks.
The same gap across four platforms
The execution model differs across platforms, but the governance gap is identical: every tool call executes unless the agent itself decides not to. There is no external admission control.
| Platform | Instruction file | What the agent can do | Built-in admission control |
|---|---|---|---|
| OpenClaw | SOUL.md |
Shell, files, web, messages, MCP tools, skills | None |
| Claude Code | CLAUDE.md |
Bash, Write, Edit, NotebookEdit, MCP tools |
None |
| Cursor | .cursorrules / .mdc |
Shell, file edits, MCP tools, tasks | None |
| Codex | System instructions | exec_command, file writes, MCP tools |
Sandbox (network-isolated, but no policy evaluation) |
Codex is worth a note: its cloud sandbox provides real isolation (no network by default), which is meaningful. But isolation is not governance. A sandboxed agent can still write PII to files and produce outputs that leak sensitive content when delivered to the user.
The point is not that these platforms are insecure. None of them provide the piece that infrastructure teams expect: an external policy evaluation layer that decides whether each tool call should proceed, independently of what the agent thinks.
What an execution boundary looks like
The fix is the same architectural pattern across all four platforms: intercept tool calls at the execution boundary, evaluate them against policies before they run, and record every decision.
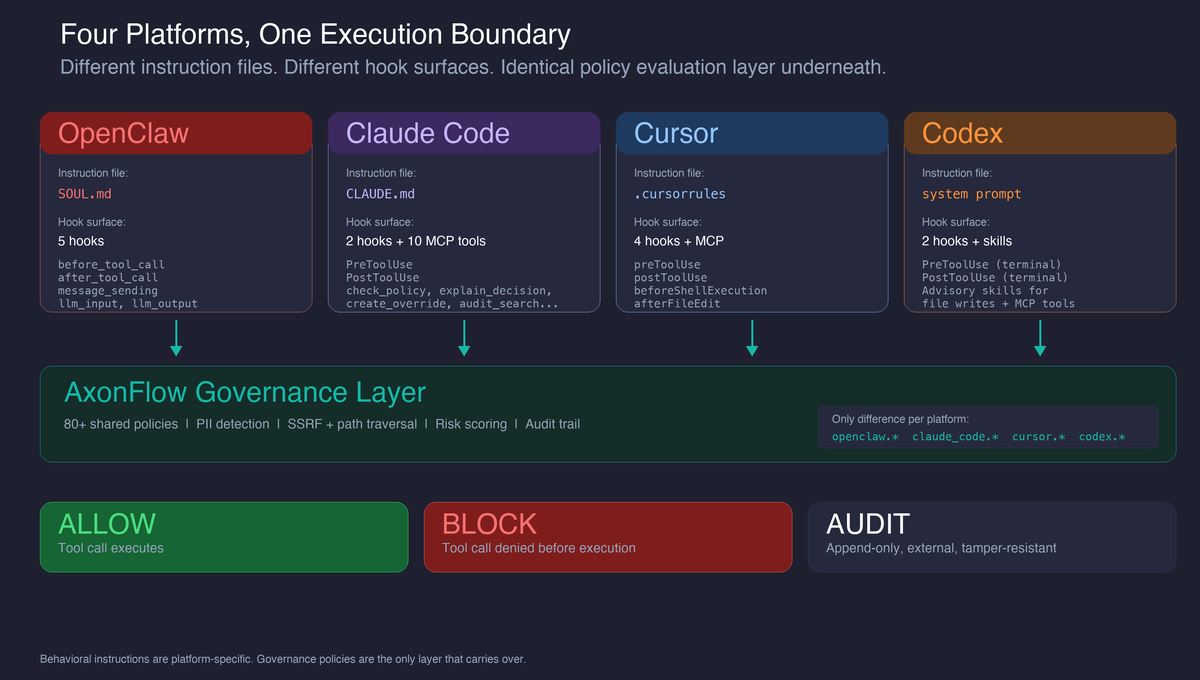
Each platform exposes this boundary differently:
| Platform | Enforcement mechanism | Coverage |
|---|---|---|
| OpenClaw | 5 plugin hooks (before_tool_call, after_tool_call, message_sending, llm_input, llm_output) |
All tool calls, outbound messages, LLM interactions |
| Claude Code | PreToolUse / PostToolUse hooks + MCP server exposing 10 governance tools (check_policy, check_output, audit_tool_call, list_policies, get_policy_stats, search_audit_events, explain_decision, create_override, delete_override, list_overrides) |
Bash, Write, Edit, NotebookEdit, all MCP tools |
| Cursor | preToolUse / postToolUse / beforeShellExecution / afterFileEdit hooks + MCP server |
Shell, Write, Edit, Read, Task, NotebookEdit, MCP tools |
| Codex | PreToolUse / PostToolUse hooks for terminal tools + advisory skills for broader tools |
exec_command enforced; other tools via skill-guided governance |
The policy set is the same across all four: 75+ policies covering reverse shells, destructive filesystem operations, credential access, download-and-execute patterns, cloud metadata SSRF, path traversal, dynamic code execution, unauthorized package installation, and PII detection. A policy that blocks curl|bash in OpenClaw also blocks it in Claude Code, Cursor, and Codex. The only difference is the connector type prefix (openclaw.*, claude_code.*, cursor.*, codex.*), which lets you write platform-specific policies when needed while sharing the baseline.
What we learned building across four platforms
Governance policies are portable; instruction files are not
This was the biggest surprise. We expected each platform’s tool model to require platform-specific policies. It did not. Tool inputs look similar enough across platforms that a single policy set covers all four.
SOUL.md is OpenClaw-specific. CLAUDE.md is Claude Code-specific. .cursorrules is Cursor-specific. If you switch platforms or run agents across multiple platforms, you rewrite your behavioral instructions from scratch.
Governance policies do not have this problem. They evaluate tool inputs at the execution boundary, and tool inputs are tool inputs regardless of which agent generated them. The governance layer is the one piece of agent infrastructure that does not have to be rebuilt when you switch platforms.
Not every platform gives you the same hooks
OpenClaw, Claude Code, and Cursor expose pre-execution hooks for all tool calls. Codex exposes PreToolUse and PostToolUse hooks for terminal commands; broader tools (file writes, MCP) rely on advisory skills that the agent can choose to ignore. We document these gaps rather than pretending all four have identical enforcement. When a platform’s enforcement surface is narrower, the plugin README says so in the first section.
The same discipline applies to OpenClaw’s tool result gap: results flowing back into the agent’s context are not scanned because the relevant hook (tool_result_persist) is synchronous and cannot call an external HTTP API. We have filed an upstream issue and document the limitation until it is resolved.
Fail-open vs fail-closed depends on the error type
A binary onError: block | allow forces a choice between “unusable during outages” and “unprotected during misconfiguration.” The better model is error classification:
- Network failures (timeouts, DNS, connection refused): transient, fail-open. The governance layer is temporarily unreachable but will come back.
- Auth errors (401, 403, invalid credentials): developer-fixable, fail-closed. Something is misconfigured and the developer should fix it before proceeding.
This distinction is identical across all four plugins. It is not a per-platform decision. It is a governance-layer design decision.
Protecting instruction files is itself a governance policy
Once you have an execution boundary, one of the first policies to add is: block writes to instruction files. Any tool call attempting to modify SOUL.md, CLAUDE.md, MEMORY.md, IDENTITY.md, or .cursorrules is intercepted and blocked before the write executes.
This sounds circular (the governance layer protecting the instruction file that the governance layer replaced), but it matters. Instruction files still shape behavior. They are useful for the things listed at the top of this post. Protecting them from tampering preserves their value for role shaping and conventions, while the governance layer handles the enforcement they were never designed for.
What this does not solve
Execution-boundary governance is not a complete security solution:
-
Plugin supply chain. The governance layer blocks malicious tool calls after a poisoned plugin is installed. It does not prevent the plugin from being installed. Marketplace integrity is an upstream problem for each platform (ClawHub, Claude Code marketplace, Cursor marketplace, OpenAI).
-
Fleet management. If you run agents across four platforms, there is no discovery mechanism that tells you which instances have governance enabled. Agent registration and fleet inventory require infrastructure that does not exist yet.
-
Model-level manipulation. If the model produces harmful outputs that do not involve tool calls, the governance layer has no visibility. It governs tool execution and output delivery, not the model’s internal reasoning.
-
Context window decay. In very long sessions, both instruction files and governance context can fall out of the model’s attention. The hooks still fire (they are code, not prompts), but the agent’s behavioral alignment may degrade. This is precisely why the enforcement boundary must be external, not prompt-based.
Instruction files shape intent. Execution boundaries enforce policy. If your agent can still reach the tool, your policy has not been enforced yet.
All four plugins are source-available: OpenClaw, Claude Code, Cursor, Codex. For the OpenClaw-specific deep dive on CVEs, ClawHavoc, and the tool result gap: SOUL.md Is Not a Security Boundary.
For the implementation details: AxonFlow security best practices, security architecture overview, and the tier-by-tier capability matrix.