A team had a workflow that retried itself when an LLM call timed out. The retry budget was set on the wrong layer, so a single bad query drained their daily quota in 90 seconds. They added a budget. The next incident was a duplicate notification because the retry didn’t know what had already executed. They added retry context. Then a regulator asked which policies had been evaluated when a particular call was approved. The audit log answered “what.” It did not answer “why.”
Three different post-mortems. Three fixes in three different parts of the agent code. None of them in the same place.
That is the shape this series has been pointing at since post one. Execution semantics, retry budgets, cost-per-outcome accounting, decision context, step-boundary gating, idempotency boundaries. Seven posts. Seven failure modes. One layer.
Every failure has the same address
Look at where each of those seven failures gets fixed.
A retry budget that has to be enforced consistently across every tool, regardless of which agent invoked it. That is not in the agent. It is at the boundary every tool call crosses.
A decision-context record that has to be written for every action, regardless of which framework dispatched it. That is not in the framework. It is at the boundary every dispatch crosses.
An idempotency contract that has to be honored across orchestrator restarts, regardless of which workflow run sent the request. That is not in the workflow. It is at the boundary every gate request crosses.
The pattern is uniform. Every cross-cutting concern lands at the layer that sees every request, every step, and every tool call. Frameworks see only the runs they happen to be executing. Agents see only the steps they happen to be deciding. Neither of them is at the right layer to enforce a property that has to hold across all of them.
That is the layer this post is about.
What kind of layer consistently solves cross-cutting concerns
Distributed systems hit this exact pattern decades ago.
The failure mode was the same shape: cross-cutting concerns (auth, rate limiting, observability, traffic policy, secrets) bolted into every service, drifting between services, mis-applied at every boundary. The fix was not “better libraries inside each service.” The fix was a separate layer that sat between services and saw every interaction.
That layer has shown up under three names, depending on what it is governing:
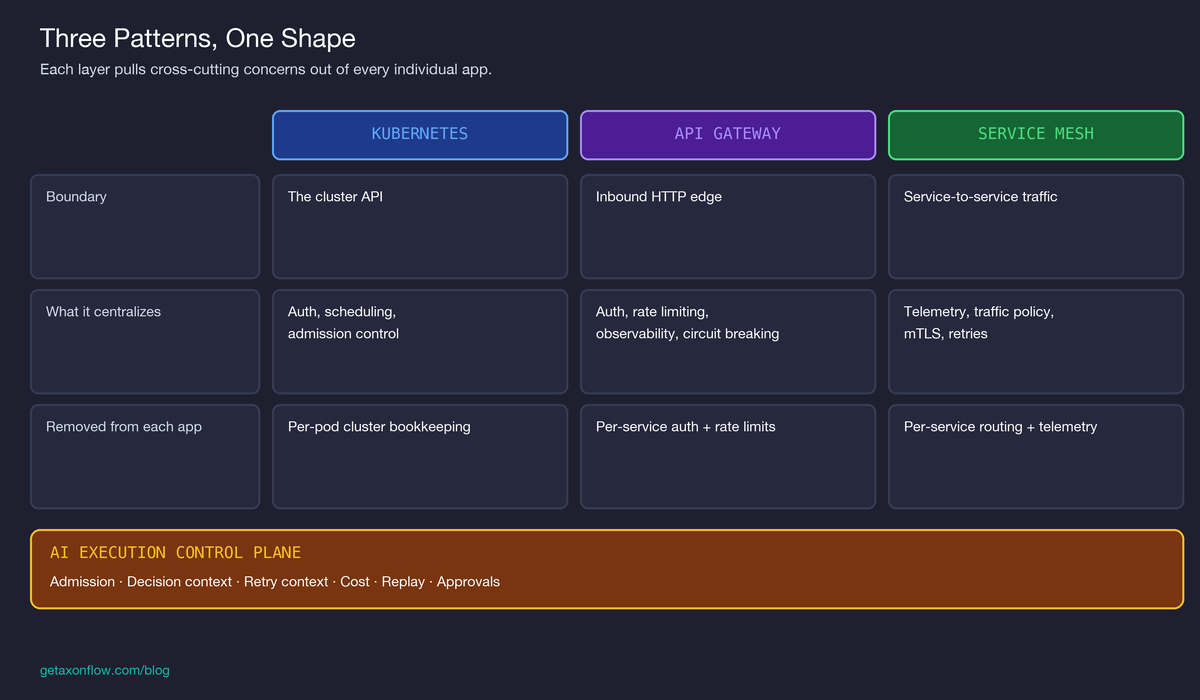
Three different patterns. One shared property: they pull cross-cutting concerns out of every individual app and put them at the boundary every request crosses.
A pattern this consistent across infrastructure layers is usually pointing at something structural. It pointed at one thing in distributed systems: certain concerns belong at a shared boundary because that is the only place they can be enforced uniformly.
The case for an AI execution control plane
AI systems are now hitting the same pattern.
The cross-cutting concerns are different in detail (policy, cost, retry context, idempotency, decision context, replay, step gating, approval queues), but the structural reason they keep landing in the wrong place is identical. In many stacks we have seen, they are bolted into agent code, drift across agents, drift across frameworks, often get re-implemented when teams switch frameworks, and fail differently in production than they did in dev.
The argument of this post is one sentence:
AI systems now need an execution control plane for the same reason distributed systems needed control planes: cross-cutting runtime concerns don’t belong inside every app or workflow.
What the layer governs:
- Admission. Every step, every model call, every tool call passes through a gate. The gate evaluates declared policy and returns allow, block, or require approval. The agent does not enforce its own admission, the same way a service does not enforce its own auth.
- Decision context. Every gate decision records the policies evaluated, the version active at decision time, the risk score, and the reason allowed or blocked. Audit becomes a function of the layer, not a feature each agent has to remember to implement.
- Retry context and idempotency. Step identity, completion status, and caller-supplied idempotency keys live at the boundary. The agent reads them. It does not own them.
- Cost. Per-tool budgets, run-level budgets, and per-tenant quotas are evaluated at the same boundary as admission. A budget exhaustion is a denied gate, not an exception thrown inside an agent.
- Replay. Every step’s gate, decision, and completion is recorded. A workflow can be reconstructed for review without the orchestrator’s cooperation.
None of those are new. We covered each of them in this series. What is new in this post is the claim that they belong together, in one layer, for the same reason that auth and observability eventually moved out of the application.
Frameworks solve adjacent problems. They make agent code easier to write. They handle conversation state, tool schemas, and the model-call protocol. They are good at what they do. They are not the right place to put a property that has to hold across every framework you might use.
Where the analogy holds, and where it breaks
The analogy is useful precisely because it stops being useful in three specific places. Naming those is part of the argument.

Holds: cross-cutting boundary. The reason a control plane works for K8s, gateways, and meshes is that the cross-cutting concerns are observable at the boundary the layer owns. AI systems have an equivalent boundary: the gate request the orchestrator sends before each step, the LLM call the agent dispatches, the MCP tool call it executes. Anything that has to hold across all three can be enforced there.
Breaks: reconciliation. Kubernetes works because cluster state is enumerable. The control plane converges actual state to declared state. AI workflows are not like this. The model decides the next step at runtime; there is no enumerable target. The control plane gates the step, it does not converge to anything. The word “reconciliation” does not transfer.
Breaks: granularity. A service mesh intercepts every byte. The execution control plane intercepts at the gate boundary. Inside a step, once admission has been granted, the agent owns the execution. Defense-in-depth at the SDK layer (callable wrappers) and at the MCP layer (input/output checks) helps here, but it does not make the gate granular at the byte level.
Breaks: business operations across runs. The cross-workflow boundary from the previous post is the working example. The layer cannot reconcile two retries of the same business operation when those retries are different workflow_ids, because business operation is not state the platform can see. We named this as unsolved in that post; it is still unsolved here. It is the part of the layer that has not been built yet, and the part where the analogy to existing control planes is the least helpful.
What this changes in practice
Two practical implications, for systems either using AxonFlow or not.
Pick the layer, then pick the framework. If the cross-cutting concerns live at the framework, the framework choice is sticky. If they live at a layer below the framework, the framework choice is reversible. Most AI architectures today have the dependency the wrong way around. Switching from LangGraph to a custom Go agent should not require rewriting your audit and policy strategy; it currently does, in most stacks we have seen.
Stop scattering the same property across N agents. A retry budget that is a feature of one agent’s code is one bug fix away from drifting against another agent’s. A decision-context recorder that lives in middleware on one framework’s adapter does not exist on another’s. The fix is not better cross-team discipline. The fix is putting the property at the layer that sees every request.
The closer
If you took your agent runtime out tomorrow and replaced it with a different framework, a different orchestrator, or a different SDK, what part of your governance, audit, idempotency, and decision-context contracts would survive the swap?
Whatever survives, that is your control plane. If nothing survives, you do not have one yet.
The seven posts before this one named seven failure modes. This one names the layer they all share. The next thing worth building, in our view, is the cross-workflow boundary that even the layer doesn’t yet handle. We’ll get there.
Related posts and implementation references
- What breaks first when LLM workflows hit production
- Orchestration is not execution control
- Why retry budgets should be per tool, not per run
- Cost per call is a useless metric for agent systems
- Audit logs are not enough. You need decision context.
- You can’t pause an AI workflow. You can only stop at the right boundary.
- Idempotency boundaries in multi-system AI automation
- Payment agent: 3-minute demo of retry and reconciliation in action
- First agent tutorial: start here
- Workflow examples tutorial: governed workflow patterns
- Payment agent retry and reconciliation tutorial
- Healthcare prior-auth tutorial: HITL on a different domain
- Workflow Control Plane: retry and idempotency
- AxonFlow platform capabilities
- AxonFlow architecture overview