A workflow tried a wire transfer. The bank API succeeded. The orchestrator crashed before it could record completion.
On retry, the workflow hit the bank again. Same Idempotency-Key. The bank correctly returned the original response. No double-charge.
But step 5 of the workflow, “notify customer,” had also run on the first attempt. And it ran again on the retry. One transfer. Two notifications. One confused customer.
The idempotency boundary that mattered was not the bank API. It was the workflow.
In our previous posts, we covered execution semantics, execution control, retry budgets, cost-per-outcome accounting, decision context, and step-boundary gating. This one is about a related blind spot: where idempotency is actually enforced in an AI system, and where it is silently absent.
The boundary mismatch
API idempotency was designed for a single HTTP call. You send a POST with an Idempotency-Key header, the server records it, and any retry within a window returns the original response without re-executing the side-effect. Stripe popularised the pattern. Most well-designed payment, messaging, and ledger APIs now offer it.
It works exactly as advertised. And in an AI workflow, that exact correctness is also exactly the wrong granularity.
An AI workflow is rarely one HTTP call. It is a sequence of model calls, tool invocations, and downstream actions. A single retry of the workflow can involve:
- the model being asked again to plan
- one or more tool calls being re-issued
- a downstream API call that already succeeded
- a notification step that has already fired
- a write to an internal ledger that is keyed differently than the external API
API-level idempotency keys protect each of those individually, if and only if the called API supports them. They do not protect the workflow’s intent. They cannot, because they cannot see it.
That is the gap.
Three boundaries, three failure modes
It helps to be precise about what is being protected at each level.

API call boundary. The narrowest scope. Protects a single outbound call from being executed twice. Owned by the called service. Useless for protecting any other side-effect that the surrounding workflow triggered before, after, or instead of the API call.
Workflow boundary. Wider. Protects every step that the workflow run is responsible for. Still bounded to one run of the workflow. Required for any AI system where a single user-facing operation spans more than one tool call or external action.
Cross-workflow boundary. The widest. Protects a business operation regardless of whether the orchestrator decides to spawn a fresh workflow to retry it. This is the boundary that matters when an entire orchestrator process crashes, when a queue redelivers a message after a long delay, or when a multi-agent system loses track of in-flight work and re-creates it from scratch.
Most production AI systems handle the first boundary because the underlying APIs handle it. The second is usually handled poorly, with ad-hoc retry counters threaded through agent code. We have not yet seen a standard, first-class treatment of the third.
What workflow-level idempotency actually requires
To enforce idempotency at the workflow boundary, the system needs three things that an API-level key alone cannot give you.
First, a record of where in the workflow the prior attempt got to. Not just “did the API call succeed,” but “did the workflow record completion of this step before the orchestrator went away.” Those are different states with different recovery rules.
Second, a stable identifier for the intent of each step, separate from any external system’s idempotency key. The bank’s reference number identifies the bank’s view of the transfer. It does not identify the workflow’s view of the transfer, which includes the surrounding steps the agent owns.
Third, a contract that retries do not silently change semantics. A retry that flips an idempotency key mid-flight, or that re-issues a step under a different key than the original gate evaluated, leaves the audit trail meaningless.
These are not exotic requirements. They are what it takes to be able to answer, after an incident, the question “did this workflow execute this step exactly once, more than once, or not at all?”
The shipped surface
In platform v7.3.0 we made these primitives first-class on the gate API.
Every gate response now carries a retry_context block:
{
"decision": "allow",
"decision_source": "cached",
"retry_context": {
"gate_count": 2,
"completion_count": 0,
"prior_completion_status": "gated_not_completed",
"prior_output_available": false,
"first_attempt_at": "2026-04-28T15:30:45Z",
"last_attempt_at": "2026-04-28T15:31:10Z",
"last_decision": "allow",
"idempotency_key": "wire:invoice-7721"
}
}
A few choices in that shape are deliberate.
Two counters, not one. gate_count tracks how many times the orchestrator asked permission to execute the step. completion_count tracks how many times the orchestrator reported completion of the step. The combination disambiguates “we re-asked but never finished” from “we finished and are re-asking” without the agent having to do arithmetic on a single overloaded attempt_number. That distinction is exactly the one that determines whether the next action is “retry the API” or “reconcile with the downstream system.”
prior_completion_status as an enum. Three values: none, completed, gated_not_completed. The third is the one most callers care about. It means: a prior gate was approved, the orchestrator went to do the work, and we never heard back about completion. That is the uncertain territory where naive retry causes duplicates and where reconciliation is the right move.
prior_output is opt-in. The field is present in the schema but only populated if the caller passes ?include_prior_output=true on the gate request. Prior output can be large and can contain sensitive payloads. Not every retry path needs to read it; the ones that do, ask for it.
idempotency_key is caller-supplied and immutable. When the agent passes an idempotency_key on the first /gate call for a step, that key is recorded. Any subsequent /gate or /complete on the same step that sends a different key is rejected with HTTP 409 IDEMPOTENCY_KEY_MISMATCH, with both expected_idempotency_key and received_idempotency_key echoed in the error envelope. Without that contract, the audit trail becomes untrustworthy: a step could appear to have been gated under one business identity and completed under another, and there would be no way to detect it after the fact.
The scope of the key in the shipped implementation is (workflow_id, step_id). That is the workflow boundary, exactly. A composite index across workflows is a different problem, which we will come back to.
The retry-policy contract
There is one ergonomic detail worth stating in the open, because it confuses people.
By default, when an agent re-gates the same step in the same workflow, the platform returns the cached prior decision. This is the right default. It means the orchestrator can be safely restarted, the agent code can have its own retry loop, and the policy engine does not re-fire on every replay.
But sometimes you actually want re-evaluation. The state of the world has changed. A risk score moved. A new policy was deployed. The original decision is now stale.
That mode is opt-in. Callers pass retry_policy: "reevaluate" on the gate request. Only then does the policy engine re-fire and produce a fresh decision. The retry-aware policy fields (step.gate_count, step.completion_count, step.prior_completion_status, step.prior_output_available, step.last_decision, step.first_attempt_age_seconds, step.idempotency_key) only become meaningful in the re-evaluation path.
That last point matters because the most common policy authors get wrong is one like “if gate_count > 3, block.” If the caller never passes retry_policy: "reevaluate", that policy never fires, because the gate hits cache. The policy is correct in isolation; the contract is what makes it useful.
Concrete example
If you would rather see the pattern run than read it, the second of the three transfers in our 3-minute payment-agent demo is exactly this scenario: the bank accepts a wire, the acknowledgement times out, the orchestrator retries, and the agent reads the retry context to reconcile rather than re-fire. The full code walkthrough lives in the payment agent retry and reconciliation tutorial. The shape is general; the specifics are payments only because payments are where this is most expensive to get wrong.
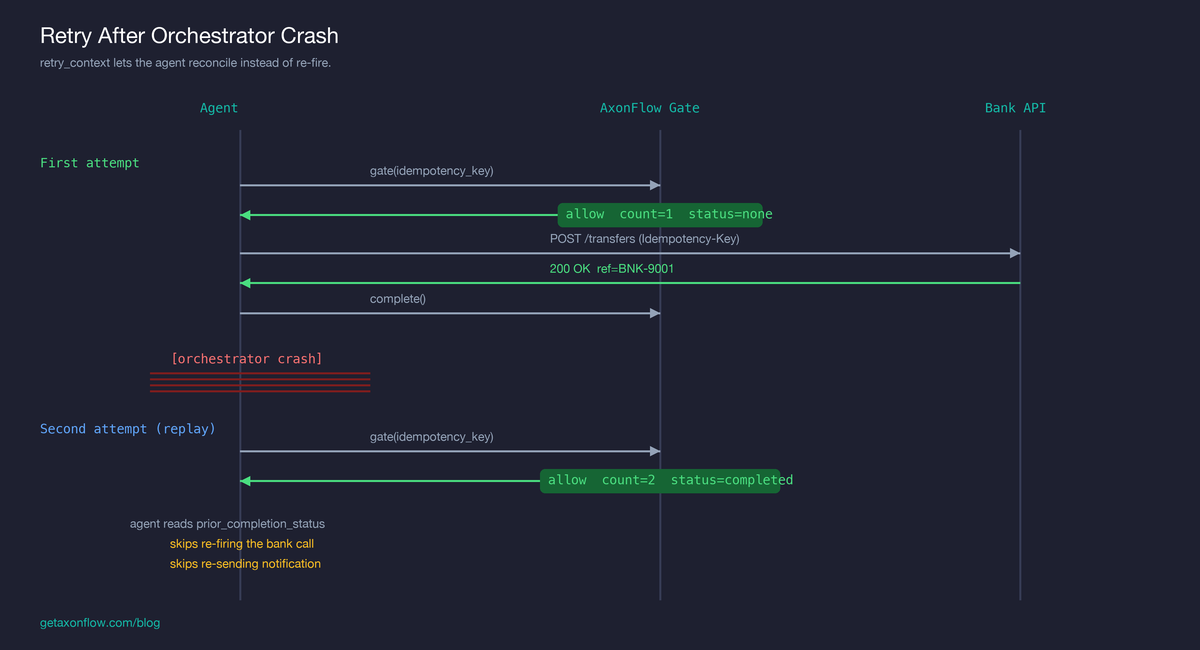
The same flow at field-level resolution:
First attempt
agent: gate(workflow=W1, step=transfer, idempotency_key="wire:inv-7721")
platform: allow, retry_context.gate_count = 1,
retry_context.prior_completion_status = "none"
agent: bank.POST /transfers (Idempotency-Key: wire:inv-7721)
bank: 200 OK, ref=BNK-9001
agent: complete(workflow=W1, step=transfer, idempotency_key="wire:inv-7721")
agent: gate(workflow=W1, step=notify, ...)
agent: send_email("Your transfer is on its way")
[orchestrator crash]
Second attempt — orchestrator restarts, retries from the beginning of the workflow
agent: gate(workflow=W1, step=transfer, idempotency_key="wire:inv-7721")
platform: allow, retry_context.gate_count = 2,
retry_context.completion_count = 1,
retry_context.prior_completion_status = "completed"
agent: [reads prior_completion_status, skips bank call,
fetches prior output via GET /workflows/W1]
agent: gate(workflow=W1, step=notify, ...)
platform: allow, retry_context.gate_count = 2,
retry_context.completion_count = 1,
retry_context.prior_completion_status = "completed"
agent: [reads prior_completion_status, skips re-sending email]
The bank’s idempotency key is doing its job throughout: even if the agent did fire the call again, the bank would return the original. But the agent now has enough information to not fire it in the first place, and to also not re-send the notification — which is the side-effect the bank’s key never could have protected.
The case where the orchestrator crashed between the bank call and the platform’s /complete call is the one prior_completion_status: "gated_not_completed" exists for. That is the agent’s signal to reconcile with the bank’s state instead of either re-firing or assuming success.
What is still unsolved
The above only works as long as the retry happens within the same workflow. The moment a fresh workflow attempts the “same” operation, the chain is broken. Different workflow_id. Different (workflow_id, step_id). The platform sees a brand new step. No prior context. No 409. No protection.
This is not a hypothetical. It happens whenever:
- a parent multi-agent process re-spawns a child agent with a fresh workflow, instead of resuming the existing one
- a queue redelivers a message after the original consumer’s lease expired
- a human reviewer triggers a retry from a UI that creates a new workflow rather than resuming the failed one
- two agents independently pick up the same task because the work-queue is at-least-once
The fix requires a different lookup: index the caller-supplied idempotency_key across workflows, scoped to a tenant and a tool identity, with a time window. Block on duplicate. Return the prior workflow’s identifier so the agent can reconcile.
That has weight. It puts a query on the gate hot path. It needs storage that can answer “have you seen this fingerprint in the last N seconds” cheaply. It needs careful tenant scoping so duplicates from one customer never leak across to another. The shipped (workflow_id, step_id) scope is deliberately narrow because it does not require any of that; cross-workflow does.
It is on our roadmap. It is not shipped. We name it explicitly here because pretending the workflow boundary is sufficient is the same kind of error as pretending the API boundary is sufficient. It is just one boundary out.
If your retry surface includes orchestrator restarts that may spawn a new workflow, agent crashes that lead to the work being re-queued, or any path where the same business operation can be initiated more than once with different workflow_ids, the cross-workflow boundary is the one you currently have to handle yourself. Either with a duplicate-detection step inside the agent, or by having every downstream API support a stable, business-level idempotency key the agent passes through.
What this changes about how to design AI workflows
Three practical implications, for systems either using AxonFlow or not.
Choose the idempotency key for the intent, not the call. A bank reference number identifies the bank’s view of the transfer. It is not the right key to identify the agent’s view, because the agent’s view includes the notification step and the ledger update. Pick a key that names what the user thinks happened. Pass it to every step the platform gates. Pass it through to every external API that supports an idempotency header. They do not have to be the same string, but they should both exist.
Treat gated_not_completed as a first-class state. It is the difference between “fire again” and “reconcile.” Most retry code today does not distinguish. Most production incidents in this space come from that.
Decide explicitly where you want re-evaluation, not just retry. Every retry point in your system is one of two things: “use the cached decision” or “ask again with the latest state.” Defaulting to the first is correct. Forgetting that the second is opt-in is how retry-aware policies silently never fire.
The closer
Idempotency in AI workflows is not a single boundary. It is at least three: the API call, the workflow run, and the business operation across runs. Each catches a different failure. The narrowest one is provided by every well-designed external API. The middle one is what platforms like ours are now shipping. The widest one is still open: we have not shipped a treatment for it, and we have not yet seen a standard one elsewhere.
The cost of getting any of them wrong is the same shape: a side-effect happens twice when the user expected it to happen once. Two notifications, two refunds, two debits, two outbound emails, two anything. The bank’s Idempotency-Key does not see them. The audit log records them as two distinct events because they were two distinct events. The customer just sees a system that cannot count.
If your AI workflow retried right now, what is the boundary at which “same operation” is actually defined in your system: the API call you made, the step the agent gated, or the user-visible outcome the customer thinks happened once?
Related posts and implementation references
- What breaks first when LLM workflows hit production
- Orchestration is not execution control
- Why retry budgets should be per tool, not per run
- Cost per call is a useless metric for agent systems
- Audit logs are not enough. You need decision context.
- You can’t pause an AI workflow. You can only stop at the right boundary.
- Payment agent: 3-minute demo of retry and reconciliation in action
- Payment agent retry and reconciliation tutorial