“Pause the workflow before it sends anything.”
This sounds simple. In a traditional batch system, you checkpoint state, stop the process, and resume later from the checkpoint. In a database migration, you commit the transaction log and pick up where you left off.
AI workflows do not really work this way.
An LLM call is not a database transaction. It has no rollback. The response is generated, the tokens are consumed, the external API was called. If a tool in your workflow booked a flight, you cannot un-book it by “resuming from checkpoint.” If a model generated a customer-facing email and an external service sent it, that email is already out in the world.
In our previous posts, we covered execution semantics, execution control, retry budgets, cost tracking, and decision context. This post is about why “pause and resume” is the wrong mental model for AI workflows, and what to build instead.
The checkpoint illusion
The instinct from backend engineering is to checkpoint. Serialize the state, write it to disk, resume later. Kubernetes does this with pod eviction and rescheduling. Database systems do this with WAL replay.
For AI workflows, checkpointing is deceptive for a few reasons:

-
LLM calls have side effects you cannot undo. A model response that triggered an API call (booking, payment, notification) cannot be reversed by replaying from a prior state.
-
Model state is not serializable. The conversation context, tool call history, and in-flight reasoning chain exist in the orchestrator’s memory. Serializing this is framework-specific and fragile. LangGraph has its own state graph. CrewAI has agent memory. AutoGen has conversation threads. There is no universal checkpoint format.
-
The world changed while you were paused. A workflow that paused for human approval at step 4 might resume hours or days later. The data it queried in step 2 may have changed. The model it planned to call in step 5 may have been deprecated. The policy that allowed step 3 may have been updated.
Checkpoint-based resume pretends time stopped. It did not.
What actually needs to happen
The real requirement behind “pause the workflow” is almost always one of these:
- A human needs to approve the next action before it executes. (Approval gate)
- A policy says this step is too risky to proceed automatically. (Risk gate)
- The system needs to wait for an external event. (Async gate)
None of these require serializing execution state. They require stopping at the right boundary and not executing the next step until conditions are met.
This is a different problem. You are not pausing a running process. You are choosing not to start the next step.
Step-boundary gating
The pattern that works is step-boundary gating: the orchestrator asks for permission before each step, and the governance layer can say “not yet.”
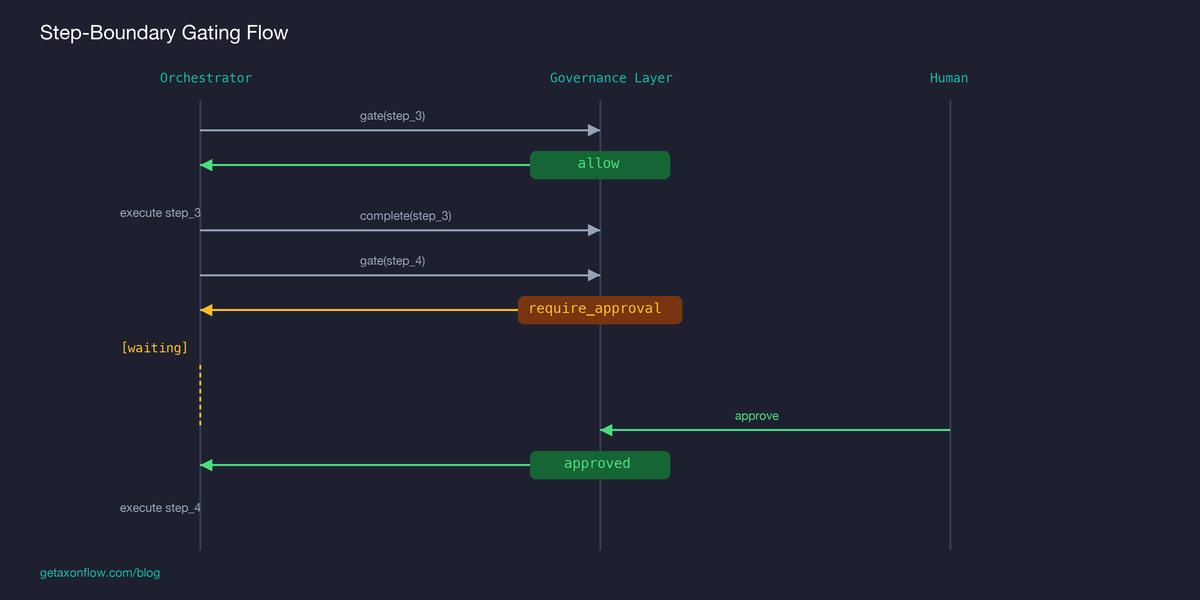
Three things matter about this pattern:
The orchestrator controls its own state. LangGraph manages its state graph. CrewAI manages its agent memory. The governance layer does not need to serialize or understand any of it. It only needs to know: “step 4 is about to happen, here is the context, should it proceed?”
The governance layer only returns three decisions. allow (proceed), block (stop), or require_approval (wait for human). There is no “pause” state in the governance system. A workflow waiting for approval is not paused. It simply has not received permission to continue.
Steps that already executed are recorded, not checkpointed. The governance layer records that step 1 was allowed, step 2 was allowed, step 3 was allowed, step 4 is pending approval. If the orchestrator crashes, the record shows where it stopped. But the orchestrator is still responsible for its own resumption logic, not the governance layer.
The approval queue problem
When a step requires approval, something needs to:
- Record that approval is needed (who, what, why)
- Notify the right person
- Accept the approve/reject decision
- Expire stale approvals so they do not hang forever
This is a queue problem, not a workflow-state problem.
The key design decision is: what happens when an approval expires?
Option A: Auto-approve after timeout. Dangerous. You are betting that the risk that triggered the approval requirement will resolve itself.
Option B: Auto-reject after timeout, abort the workflow. Safe but disruptive. If the approver was on vacation, the workflow fails and the orchestrator has to decide what to do next.
Option C: Auto-reject after timeout, make re-submission explicit. The step is rejected, the workflow reflects that rejection, and a later retry has to go through a new approval cycle instead of silently continuing.
Operationally, Option C is usually the cleanest model. It keeps the default safe, but does not pretend the workflow was ever paused. The workflow is not running. It is waiting for a specific condition before the next step can begin.
What “resume” actually means
When someone says “resume the workflow,” they usually mean one of two things:
Case 1: The approval came through. The orchestrator was waiting for the gate to return allow. The approval event fires, the gate returns allow, and the orchestrator proceeds. This is not “resume.” This is “the condition was met.”
Case 2: The orchestrator crashed and restarted. The orchestrator needs to figure out which step it was on and whether it should retry. This is the orchestrator’s responsibility, not the governance layer’s. The governance layer can tell you: “step 4 was the last step gated, and this was the decision.” The orchestrator uses this to determine where to pick up.
In both cases, no shared checkpoint is needed. The governance layer has a record of gate decisions. The orchestrator has its own state persistence mechanism, whether that is LangGraph checkpoints, framework memory, or something custom.
The two systems do not need to share a checkpoint format. They need to share a boundary: “step N, decision, timestamp.”
When this breaks
Step-boundary gating assumes the orchestrator calls the gate before every step. If the orchestrator skips the gate (bug, misconfiguration, or deliberate bypass), the governance layer has no opportunity to block.
Three safeguards help:
-
SDK enforcement. The governance wrapper intercepts step transitions at the framework level. In a LangGraph adapter, every node entry triggers a gate call. The developer does not manually thread gate logic through every node.
-
Audit gap detection. If step 5 completes but step 4 was never gated, the audit trail has a gap. This is detectable from the timestamps and execution records.
-
Post-execution recording. Even if the gate was bypassed, the post-step record still shows that something executed. This does not prevent the action, but it leaves evidence for incident review and compliance follow-up.
None of these are perfect. A governance system that depends on the caller to invoke it can always be bypassed by a caller that does not. The mitigation is defense in depth, not one magical enforcement point.
The cost of getting this wrong
A financial services workflow that auto-approves a blocked transfer because the approval timed out is a compliance incident. A healthcare workflow that resumes from a stale checkpoint and sends a patient notification based on outdated records is a liability event. A content moderation workflow that skips the approval gate because the orchestrator crashed and restarted mid-step is a trust failure.
The common thread: these are not technical failures. They are boundary failures. The system did not have a clear answer to “should this step execute right now, given everything that has happened?”
Step-boundary gating does not prevent all of these. But it gives you a decision point at every step transition. When the regulator, auditor, or incident reviewer asks “why did step 7 execute,” you can point to a specific gate decision, with the policy that was evaluated, the context that was provided, and the timestamp of the decision.
That is not a checkpoint. It is a decision record. And it is what “pause and resume” should have meant all along.
What is your boundary between “the orchestrator decides” and “a governance layer decides”? In your system, who has the authority to say “not yet”?