Your orchestration graph can run exactly as designed and still produce incidents.
Tools fire. Models respond. Branches resolve.
Yet you end up with duplicate writes, partial state, and postmortems built from log guesses. We traced one production incident to a retry that re-created a CRM record — the orchestrator had no idea the first write had already committed.
That is usually not a graph-design problem. It is a layer-boundary problem.
In our previous post, we covered what breaks first in production LLM workflows. This post focuses on the architectural distinction underneath those failures.
Orchestration and execution control are different jobs
Orchestration frameworks are built for graph coordination:
- dependency ordering
- branching and fan-out/fan-in
- retries and scheduling
- tool routing
Execution control is a separate concern:
- should this step run now?
- was this step already committed?
- which policy context admitted it?
- if a call timed out, do we replay or resume?
- can we reproduce the decision later?
You need both layers in production.
Graph position is not committed state
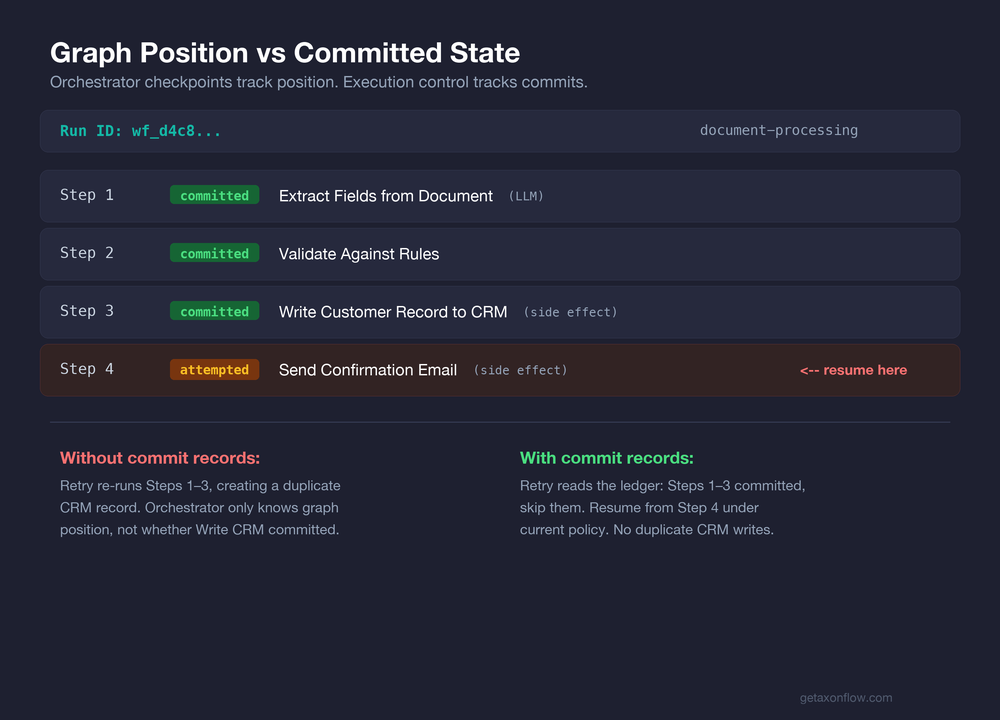
Consider a document-processing workflow:
- extract fields from document (LLM)
- validate against rules
- write customer record to CRM (side effect)
- send confirmation email (side effect)
Step 3 commits in CRM. Step 4 times out.
Your orchestrator can tell you where the run was in the graph. It usually cannot prove whether step 3’s side effect committed — not unless commit state is persisted outside the graph.
That is where duplicate writes and unsafe retries begin.
Minimal execution-control contract
Execution control does not replace orchestration. It wraps side-effecting boundaries with explicit state.
- Durable run identity independent of process lifecycle.
- Per-step gate checks before execution (
allow,block,require_approval). - Commit records after successful side effects.
- Resume semantics based on commit state, not checkpoint position.
- Decision provenance (policy version, risk/budget context, admission result).
Without this contract, retries become replay by accident.
Integration pattern (orchestrator + control layer)
The practical shape is simple: keep your orchestrator, add gate + commit around side-effecting steps.
# Register workflow run once
workflow = await client.create_workflow(
CreateWorkflowRequest(
workflow_name="document-processing",
source=WorkflowSource.LANGGRAPH,
)
)
# Gate check before side effect
gate = await client.step_gate(
workflow_id=workflow.workflow_id,
step_id="write-crm",
request=StepGateRequest(
step_name="Write Customer Record to CRM",
step_type=StepType.TOOL_CALL,
),
)
if gate.is_allowed():
result = write_to_crm(customer_data)
# Record committed outcome
await client.mark_step_completed(
workflow.workflow_id,
"write-crm",
MarkStepCompletedRequest(output={"crm_id": result.id}),
)
This is the execution-control pattern used in AxonFlow: gate first, commit record second, resume from committed state.
Mental model
Orchestration decides what should run next.
Execution control decides whether it is allowed to run and records what actually committed.
Litmus test
If your orchestrator replays from a checkpoint, can your system distinguish steps that were attempted from steps that were committed?
If the answer is no, orchestration and execution control are still conflated. That works until retries meet real side effects.