Every production AI system has audit logs.
Most of them record the wrong thing.
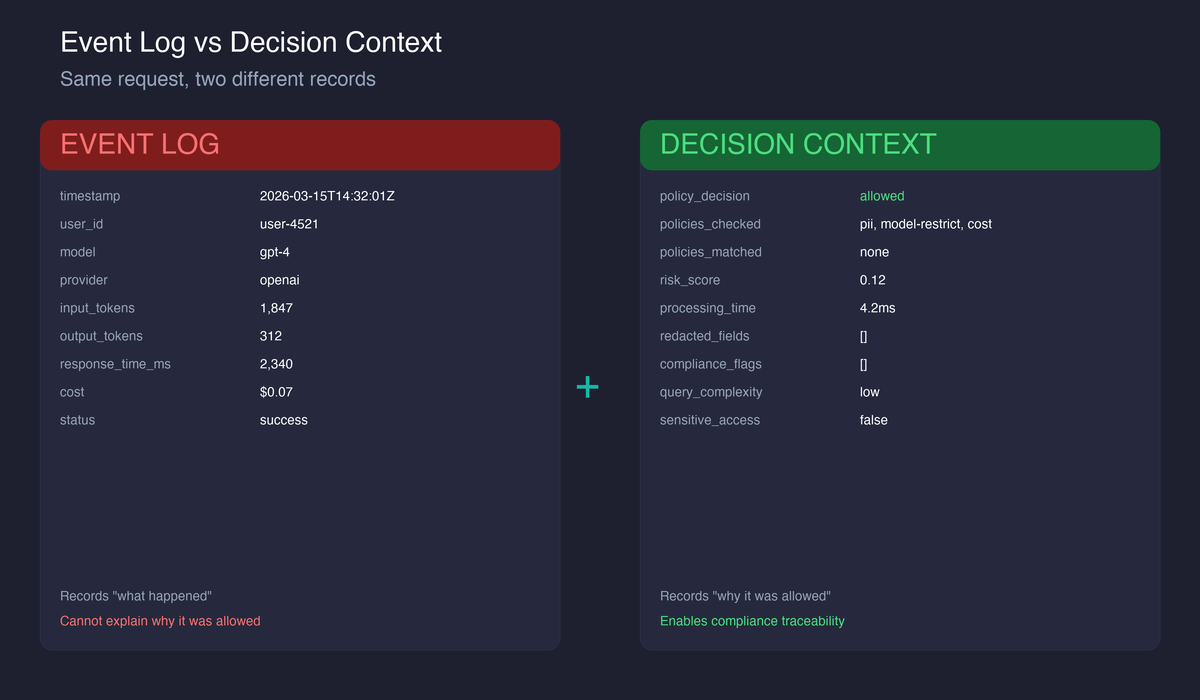
They capture what happened: which model was called, what the input was, what the output was, how long it took, how much it cost. This is necessary but not sufficient. A compliance reviewer does not ask “what happened.” They ask “why was this allowed to happen.”
We ran into this on a document-processing workflow that handled PII. The audit trail showed every LLM call with timestamps, models, and token counts. When a reviewer asked why a specific call containing credit card numbers was allowed through to an external provider, the logs had no answer. The call was logged. The policy evaluation that determined it should be allowed was not.
In our previous posts, we covered execution semantics, execution control, per-tool retry budgets, and cost tracking. This post is about the missing layer in most AI audit trails: the decision context that explains why each action was permitted.
What audit logs actually capture
A typical AI audit log entry looks like this:
{
"timestamp": "2026-03-15T14:32:01Z",
"user_id": "user-4521",
"model": "gpt-4",
"provider": "openai",
"input_tokens": 1847,
"output_tokens": 312,
"response_time_ms": 2340,
"status": "success"
}
This tells you who called what model, when, and how much it consumed. It is an activity log. It answers “what happened.”
It does not answer:
- Was this call evaluated against any policies before execution?
- Which policies were checked? How many matched?
- Were any policies violated and overridden?
- What was the computed risk score?
- Was PII detected in the input? If so, was it redacted or allowed through?
- Why was this specific model permitted for this user and this query type?
Without these answers, an audit log is a record of activity, not a record of governance.
The gap: event logs vs admission records
The distinction maps directly to a pattern that infrastructure engineers already know. In Kubernetes, the audit log records API requests. The admission controller records why each request was allowed or denied, which validating webhooks ran, and what mutations were applied.
AI systems need the same separation:
AI Request"] --> B["Policy
Evaluation"] B --> C{Decision} C -->|allowed| D["Execute"] C -->|blocked| E["Reject"] C -->|redacted| F["Execute
with redaction"] D --> G["Event Log
who / what / when / cost"] E --> G F --> G B --> H["Decision Context
policies / risk / redactions"] style G fill:#FECACA,stroke:#991B1B style H fill:#BBF7D0,stroke:#166534 style B fill:#DBEAFE,stroke:#2563EB style C fill:#DBEAFE,stroke:#2563EB
Both records are attached to the same request. Both should be treated as append-only. But only the decision context lets you reconstruct the reasoning that led to a permitted action.
Why this matters for regulated environments
EU AI Act Article 12 requires “automatic recording of events” for high-risk AI systems, with logging that enables “the tracing back of the system’s operations.” In practice, event-only logging (inputs, outputs, timestamps) is usually not enough to satisfy traceability expectations. Reconstructing why an action was permitted requires knowing which policies were evaluated, what they found, and how the system arrived at its decision.
If a model call processed health data and sent it to an external provider, the audit trail needs to show that the PII detection policy ran, what it found, and why the call was still permitted (for example: the detected entities were below the blocking threshold, or the data was redacted before transmission).
RBI guidelines for AI in banking point in the same direction. The framework expects documented evidence of risk assessment at the point of AI decision-making. In practice, this means the audit trail should capture which risk policies were evaluated, what their thresholds were, what the computed risk was, and whether the risk fell within approved bounds. An event log that says “model called, response returned” does not provide that evidence on its own.
SEBI in India requires AI/ML models used in securities markets to maintain audit trails that demonstrate how decisions were made, not just that they were made. For trading systems and advisory platforms, the ability to reconstruct the policy evaluation chain behind each AI action is a regulatory expectation, not a nice-to-have.
MAS in Singapore takes a similar position through its FEAT principles (Fairness, Ethics, Accountability, Transparency). The accountability pillar specifically expects that AI-driven decisions can be explained and traced back to the factors that influenced them. For financial institutions operating under MAS guidelines, an audit trail that records activity without recording the governance reasoning behind each decision leaves a gap during supervisory review.
What decision context looks like in practice
A complete audit entry with decision context captures both the activity and the admission reasoning:
{
"timestamp": "2026-03-15T14:32:01Z",
"request_type": "llm_call",
"user_id": "user-4521",
"tenant_id": "finserv-team",
"query_hash": "a3f2b1...",
"provider": "openai",
"model": "gpt-4",
"response_time_ms": 2340,
"tokens_used": 2159,
"cost": 0.07,
"policy_decision": "allowed",
"policy_details": {
"applied_policies": ["pii-detection", "model-restriction", "cost-limit"],
"risk_score": 0.12,
"processing_time": 4.2
},
"redacted_fields": [],
"compliance_flags": [],
"security_metrics": {
"risk_score": 0.12,
"policies_applied": 3,
"query_complexity": "low",
"sensitive_access": false
}
}
Every field after policy_decision is decision context. It was absent from the simple event log at the top of this post.
The same pattern applies to workflow step gates. When an external orchestrator (LangGraph, CrewAI) checks whether a step is allowed to proceed, the gate check produces a decision with reasoning:
{
"operation": "workflow_step_gate",
"workflow_id": "wf_a3f2b1",
"step_id": "step-2-extract",
"step_type": "tool_call",
"decision": "block",
"reason": "GPT-4 not allowed in production workflows",
"metadata": {
"model": "gpt-4",
"provider": "openai",
"policies_evaluated": 3,
"policies_matched": 1,
"tool_name": "extract_data",
"tool_type": "function"
}
}
This entry tells you not just that step-2 was blocked, but why: which policy matched, what the step was trying to do, and what model/provider combination triggered the block. Six months later, when someone asks “why did workflow wf_a3f2b1 fail on March 15,” the answer is in the audit trail, not in someone’s memory.
The five fields most audit systems miss
Based on what we have seen in production audit trails, these five fields are consistently absent:
1. Policies evaluated (not just policies matched)
Most systems log which policies triggered an action. Few log which policies were evaluated and did not trigger. The absence of a match is information. If a PII detection policy was checked and found nothing, that is evidence that the system looked for PII and determined it was clean. If the policy was never checked, that is a gap.
2. Risk score at point of decision
Some systems compute risk scores but only log them when they exceed a threshold. The score at the point of every decision, whether it triggered action or not, is what makes the audit trail reconstructible.
3. Policy version
Policies change over time. A call that was allowed under policy version 3 might be blocked under version 4. Without recording which version of each policy was active when the decision was made, you cannot determine whether a past decision was correct under the rules that existed at the time.
4. Redaction details
When PII is detected and redacted before reaching the LLM, the audit trail should record what was redacted and how. “3 fields redacted” is better than nothing. “SSN in field ‘customer_id’ masked to ‘*--1234’” is what a compliance reviewer needs.
5. Admission source
Was this call allowed because no policies matched (default-allow), because a matching policy explicitly permitted it, because an admin override was in effect, or because the system was operating in fail-open mode due to a policy engine outage? The pathway to “allowed” matters as much as the decision itself.
Recording decision context without slowing down the hot path
The objection teams raise is latency. Policy evaluation adds processing time. Recording detailed decision context adds write volume.
This is a valid concern with a known solution. The policy evaluation itself runs in the hot path because it determines whether the call proceeds. The audit write does not need to be synchronous. A batch writer that flushes every N entries or every M seconds keeps the hot path under 10ms while ensuring the audit trail is durable within a bounded window.
In practice, policy evaluation adds 2-5ms to the request path. The audit write is asynchronous. The total overhead is the policy evaluation time, not the logging time.
One way to implement this is through an audit logger that captures decision context alongside every policy evaluation. Here is how AxonFlow handles it: gateway and proxy mode requests produce an audit entry with the policy evaluation result, risk score, and any redactions applied. Workflow step gate decisions log which policies were evaluated, how many matched, and the tool context when present. The batch writer flushes to PostgreSQL every 100 entries or every 5 seconds, whichever comes first.
The question to ask your audit trail
Pull any audit entry from your production AI system. Can you answer these questions from that single entry, without looking at any other system?
- Which policies were evaluated?
- What was the risk score?
- Were any fields redacted? Which ones?
- Which version of each policy was active?
- Was this allowed by default or by explicit policy?
If the answer to any of these is “I would need to check somewhere else,” your audit trail records activity but not governance. The two look similar in calm conditions. They are very different during an incident review or a compliance audit.